主要工作
本文将面部特征点检测问题看作像素级的分类问题,提出了一种级联主干分支全卷积网络BB-FCN用于面部特征点检测,包括两部分:(1)主干网络,用于粗粒度地检测面部特征点的位置;(2)分支网络,更进一步地分别对各个面部特征点作细化处理。该工作解决了以下问题:
- 非受控环境下的面部特征点检测,包括不确定的人脸数量、位置、动作、光线等。论文提出的方法能够在没有预处理的前提下对非受控环境有很好效果;
- 性能与检测效果的冲突:Boosted-cascade-based fast face detectors虽然速度较快,但仅在正脸上取得良好效果;accurate deformable-part-based models虽然能够得到更精确的结果,但是由于过于复杂速度较慢。同时,人脸检测需要消耗数秒,导致其不实用。
该模型的效果能够在不受控环境中获得很好的效果,而不需要预处理过程。同时,为了训练模型在非受控环境下的鲁棒性,论文还建立了一个SYSU16K数据集,包含非受控条件下,光照、动作、分辨率变化很大的16,000张图片。
具体方法
问题定义
考虑非受限的输入图像$I$,我们需要对每张脸检测$K$个特征点(例如$K=5$时,认为每张脸5个特征点,分别是左右眼、鼻子、左右嘴角;另外,$K$可改变提供了模型的灵活性)。对于图像$I$的特征点检测即得到以下点集:
$Det(I)={(x_i^k,y_i^k)}_{i,k}$,其中,$k=1, 2, …K$,$i$代表第$i$张脸。
在该论文中,把特征点检测看作了一种”像素级分类“的问题,类似于图像分割。在此之前,人脸特征点检测一般将该问题构建为两种问题,模板拟合问题或回归问题:
- 模板拟合问题,即建立面部模板来对输入的人脸进行拟合。将人脸特征点检测问题看作模板拟合问题有两种方法:对于全局的特征提取的方法,或按照面部模板对局部特征提取的方法;后者一般比前者鲁棒性更强,因为局部检测能够避免光照和遮罩的问题。
- 回归问题。回归问题可以分为映射问题和级联回归模型。直接映射是指将图像内容通过回归映射至特征点的坐标;级联回归模型是以一个初始的面部形状开始,用回归器做图形优化,不断迭代直至收敛。
通过将特征点检测问题转换为像素级分类的问题,就可以借鉴图像像素级分割、实体检测的方法,选用在该任务中表现很好的FCN(全卷积神经网络),看作对该图像的深度特滤波器;同时,FCN可以天然地支持对任意大小的图像输入,并映射至对应的空间中。在论文的方法中,对每个位置的预测值,可以看作为一组的滤波器应用在对应感受域上的结果。一组优秀的滤波器需要在正确的位置得到高的响应值,而在其它位置响应值结果要低。为此,定义滤波器$F_{W^k}$,$W^k$代表第$k$类特征点的模型参数;定义$P$为一个接受域。一个理想的模型输出如下:

更进一步地,利用大小为$(w, h)$的窗口对图像进行接受域的采样,在$I$上构建了一个相应图$F_{W^k}*I$,坐标$(x, y)$对应的点的响应值为:
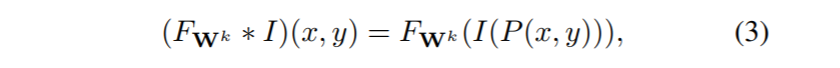
得到全图的响应值后,设置一个阈值$\theta$,中心点的响应值大于$\theta$的点即为我们要求的点集$Det(I)$:
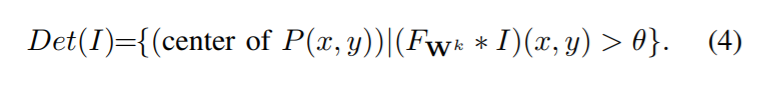
模型结构
论文指出,由公式(3)可以看出,运算速度与精确度存在对抗;即当我们取的感受域越重叠(密集)时,我们的准确率越高,但为了提高速度,我们又应该粗粒度地选区感受域。为此,一般考虑结合粗粒度和细粒度的模型,构建一个级联模型。在论文的方法中,该级联模型分为两部分:
- 相对低分辨率的图像 -> 粗粒度相应图
- 粗粒度相应图->以粗粒度特征点为中心选区局部区域->每个局部区域得到的细粒度相应图
以上步骤避免了对整张图进行细粒度的操作,提升了速度;对概率较高的位置(粗粒度相应图选择的特征点周围)做了进一步细化,保证了准确率。该级联模型被论文称为BB-FCN,即Backbone-Branch FCN,如下图所示:
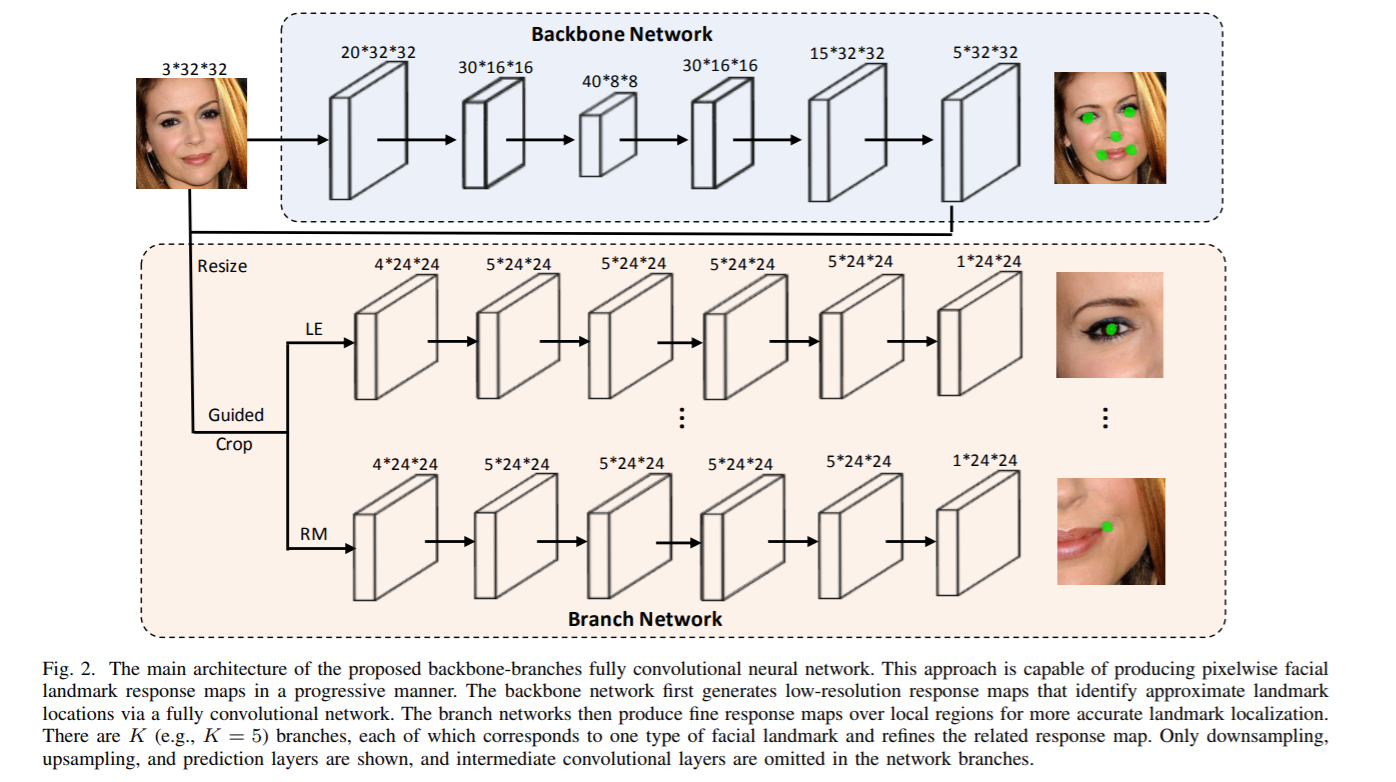
如图,主干(backbone)网络如前所述,通过全卷积神经网络提取出粗粒度的区域(例如眼镜、鼻子);分支(branch)网络由K个分支组成,每一个分支负责一个特征点类别,对前面所提到的不同特征点的粗粒度区域作进一步的细化操作,例如在左眼的区域范围内找到瞳孔。
主干网络
主干网是一个FCN,可以有效地为输入图像生成一个初始的低分辨率响应图。当在对不受限的图像面部标志进行定位时,它可以帮助我们利用阈值,拒绝大多数背景区域。定义$H^k(I;W_c)$代表第$k$类特征点在图像$I$对应的响应图,$W_c$为模型参数。可以利用上述的公式(3)来得到对应位置的响应值。主干网络的损失值定义为:
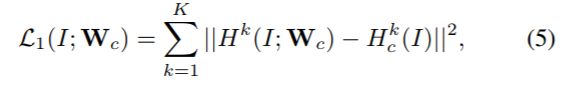
其中,$H_c^k(I)$为ground-truth。
在训练阶段,将人脸从不受限的拥挤环境中截取出来,并降低至32*32的分辨率中;同时,主干网络不对特征点作区分。这两个训练设置是为了让模型隐式地学到在一个人脸的各个特征点之间的相对约束。例如,模型可以学到两眼之间偏下一般对应鼻子这类信息。
分支网络
分支网络由$K$个不同的分支组成,每个分支对应一种特征点。输入为原始图像与主干网络输出响应图的对应位置叠合,形成RGB+主干输出的4通道图作为输入。为了更好地检测特征点,将输入的原始图像resize为64*64,主干网络生成的响应图也是如此;每一个特征点对应的输入图为24*24,即前文提到的以粗粒度landmarks为中心的方形区域。
与主干网络类似地,设置$H(P;W_f^k)$代表在区域$P$中的响应热力图,$W_f^k$为模型参数。损失值为:
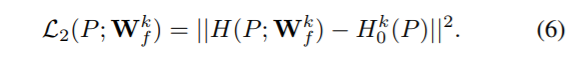
训练设置
Ground-Truth的生成
一般地认为,将landmarks对应的坐标设为1,其它位置设为0即可。然而由于标注的偏差,可能存在多个孤立的特征点于同一区域内,都可以认为是正确的。因此论文提出用区域代替原本的孤立点作为ground-truth的特征:如下图的嘴角,用一个区域代替原本的landmark点:
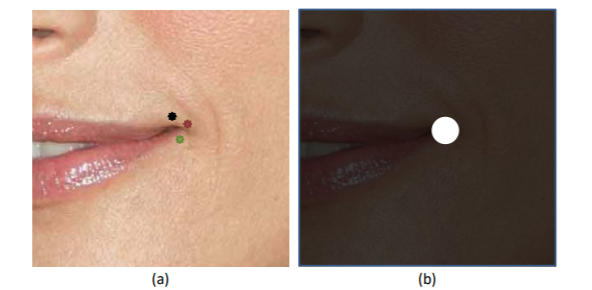
同时,对粗粒度和细粒度的区域范围做了区分,分别是$R_c$(coarse,粗粒度)与$R_f$(fine,细粒度),显然需要$R_c>R_f$,即要求细粒度模型获得更加精准的位置。
选择响应图训练
我们知道,对于一个图像而言,landmarks所占据的区域是远少于其它的,因此我们可以看作是样本的极大的不平衡,即正例过少。因此,论文采用了一种选择性方案,即随机选择与ground-truth响应图中的landmarks位置相同数量的非landmarks位置来传播误差,同时抑制误差反向传播过程中所有其他非地标位置。对于一些看不见的landmarks或背景图像,landmarks没有正区域,我们只选择一小部分非landmarks位置进行传播。这种选择性的训练方案对于确保了训练的收敛。此外,在验证集的loss下降停止后,选择hard negative samples(输出值过大的负例)进行反向传播。通过这种方法,能够定向地惩罚一些很明显的错误结果。
其它的训练细节(包括优化器、超参数、样本划分等)详见论文III-E部分,不再细述;特别地,对于受控和非受控环境论文有不同的设置。
实验结果
由于现有的数据集过小,且采样过于狭窄(有的只有正脸),因此论文建立了一个名为SYSU16K的数据集,包括7k+的非受控图像。同时从Pascal-VOC2012选取了7000+自然风景图作为负样本。
论文在LFPW, AFW, AFLW, 300W 数据集上做了测试。度量为:
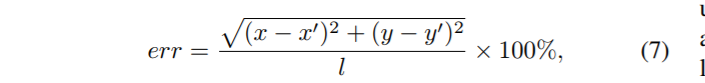
其中,$l$为眼间距。
整体效果:可以看到,对于非受控条件,即便人脸数量、人脸位置未知,模型依然能够给出很好的效果。

级联效果:通过控制是否使用分支网络来衡量粗细粒度级联模型带来的提升,可以看出,采取了级联效果的AUC在所有的分类器不同的人脸数量中都是最高的。
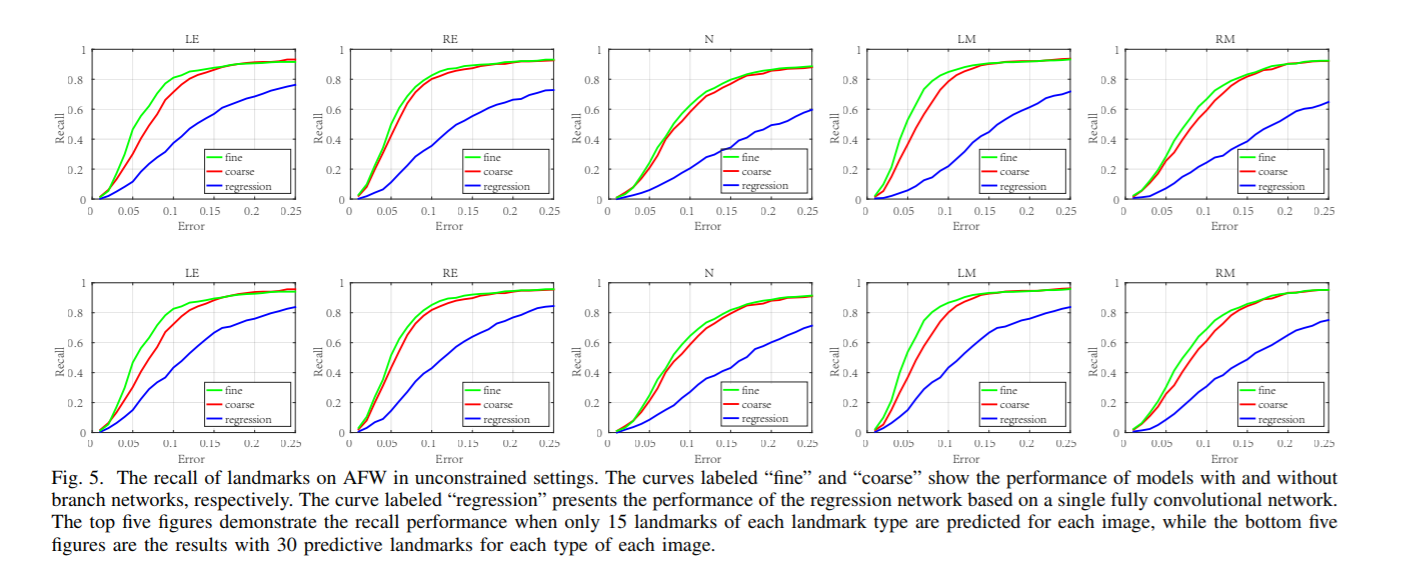
将分支网络对主干网络细化的效果进行可视化:

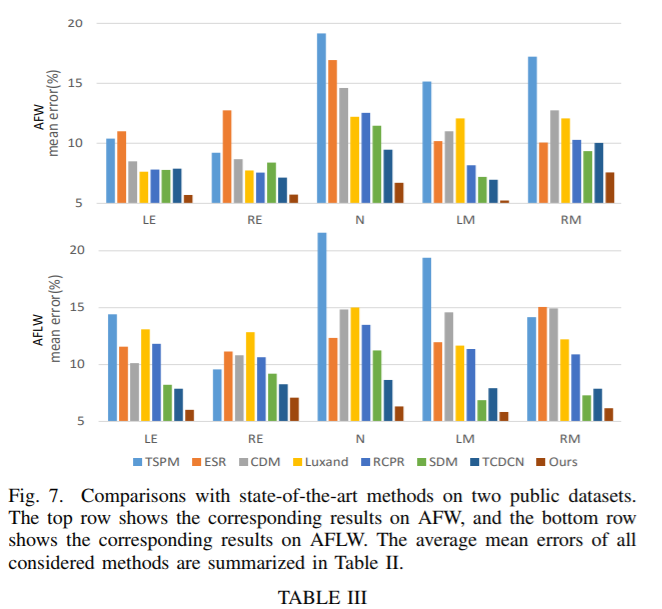
与其它方法的对比:错误率低于state-of-the-art方法:
鲁棒性测试:在不同的分辨率、光照、人脸、姿势中的效果:

更密集的landmarks探测,即改变$K$的大小:

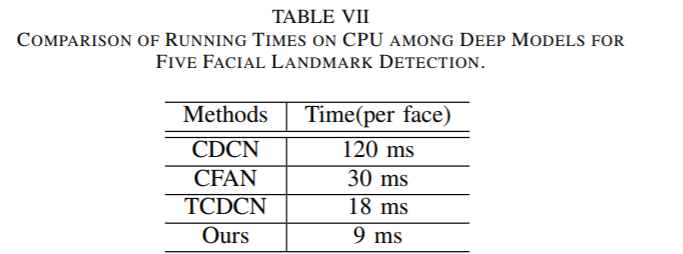
运行效率:
总结
笔者认为这篇论文有以下几个亮点值得我们借鉴学习:
- 将特征点检测转换为像素级分类问题,不仅通过概率热力图能够对实验结果进行直观的表达,而且能够借鉴在该领域上表现优秀的FCN模型;FCN除了其性能优秀外,还能够对任意大小的图像输入进行支持。
- 结合粗粒度与细粒度两阶段的级联策略,能够在速度和准确率上都得到较好的效果。粗粒度即可以是预检测目标位置的大致范围,也可以是降低图像分辨率;
- 主干网络的训练设置,以单独人脸作为训练输入,且将所有特征的响应图共同生成,这一细节能够隐式让模型学到不同特征点间的约束;
- 考虑到了人为标注的误差,用区域代替孤立点作为ground-truth;
- 在真值响应图上进行选择训练,保障了样本的均衡性;
- 在验证集停止下降的时候,利用hard negative samples进行反向传播;
- 建立了自己的in the wild 数据集,并在VOC2012上的自然分类中采样了负样本。